아래와 같은 문제상황을 가정하여 생각해본 결과,
I/O부하 방지를 위한 DB이중화 (main-replication)을 도입해야겠다는 생각이 들어 이를 진행하게 되었다.
https://desirelsw.tistory.com/170
단일 서버 성능개선 트러블 슈팅
[프로젝트 현 상황] > E커머스 웹 구현중 (ex. 쿠팡, G마켓) > 특정 시간대에 특정 상품의 재고한정 특가이벤트 기능 추가예정 https://github.com/OnNaNOn/OMG GitHub - OnNaNOn/OMG Contribute to OnNaNOn/OMG development by
desirelsw.tistory.com
깃허브 이슈는 아래와 같다
https://github.com/OnNaNOn/OMG/issues/178
I/O부하 방지를 위한 DB이중화 (main-replication 도입) · Issue #178 · OnNaNOn/OMG
💡 이슈 내용 단일 DB로 운영할 시에 벌어지는 문제 (I/O부하)에 대한 해결방안이 필요하다. 🔎 문제 분석 현재 프로젝트는 일 평균 사용자가 10만명인 상태임. 이를 단일 DB로만 운영할 시에 I/O부
github.com
아래에서는, 어떻게 Main-Replication을 적용할 수 있게 되었는지와 그 해결과정을 적으려고 한다.
Main-Replication 설명
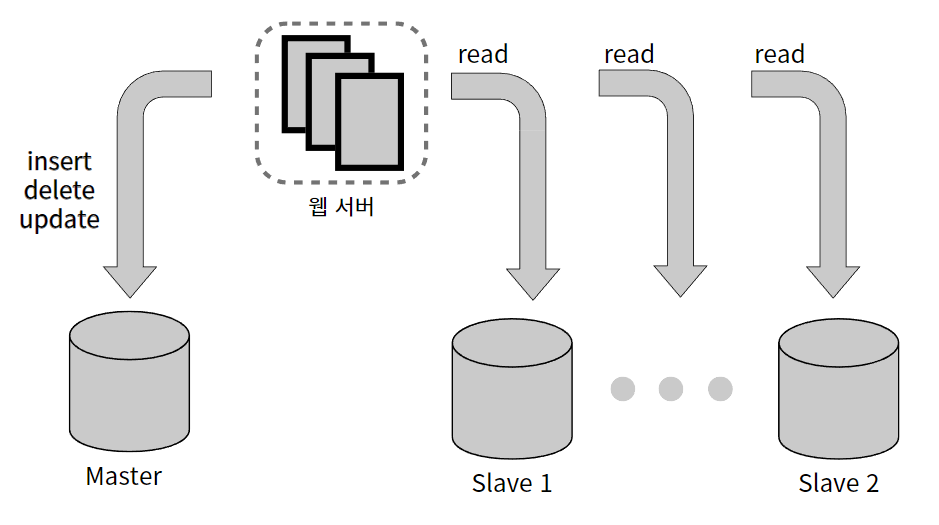
웹 계층은 로드밸런서로 인해 부하 분산을 한다면 데이터 계층은 어떻게 부하를 분산해야 하는가??
데이터 계층의 부하를 분산시키는 방법으로 주(Main)-부(Replication)관계를 설정하고 데이터 원본은 주 서버에, 사본은 부 서버에 저장하는 방식이 있다. 즉, 데이터베이스 다중화라는 기술로 해결할 수 있다.
쓰기 연산(write operation)은 메인에서만 지원하고,
부 데이터베이스는 주 데이터베이스로부터 그 사본을 전달받아 읽기 연산(read opertation)만을 지원한다.
데이터베이스를 변경하는 명령어들, 가령 insert, delete, update 등은 주 데이터베이스로만 전달되어야 한다.
대부분의 애플리케이션은 읽기 연산의 비중이 쓰기 연산보다 훨씬 높다.
따라서 통상 부 데이터베이스의 수가 주 데이터베이스의 수보다 많다.
데이터베이스를 다중화하면 다음과 같은 이점이 있다.
- 더 나은 성능: 주-부 다중화 모델에서 모든 데이터 변경 연산은 주 데이터베이스 서버로만 전달되는 반면 읽기 연산은 부 데이터베이스 서버들로 분산된다. 병렬로 처리될 수 있는 질의(query)의 수가 늘어나므로, 성능이 좋아진다.
- 안전성(reliability): 자연 재해 등의 이유로 데이터베이스 서버 가운데 일부가 파괴되어도 데이터가 보존될 수 있다.
- 가용성(availability): 데이터를 여러 지역에 복제해 둠으로써, 하나의 데이터베이스 서버에 장애가 발생하더라도 다른 서버에 있는 데이터를 가져와 계속 서비스를 할 수 있게 된다.
데이터베이스를 다중화하게 될 경우의 구성은 다음과 같다.
[STEP 01. AWS 설정]
01-1. Read Replica 생성

01-2. 읽기 전용 복제본 생성 옵션
- DB 인스턴스 식별자 작성

- 스토리지 자동 조정 활성화 OFF

- 퍼블릭 액세스 가능

- 읽기 전용 복제본 2개 생성
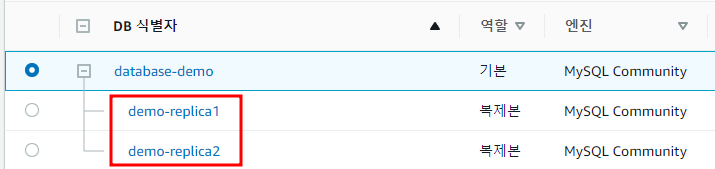
※주의사항※
복제본의 가용영역은 꼭 main RDS와 같은 가용영역으로 설정해야 한다!
ex) 아래 이미지

[STEP 02. Spring 설정]
구성
- @Transactional(readOnly = true) 인 경우는 Replication DB 접근
- @Transactional(readOnly = false) 인 경우에는 Main DB 접근
[필자가 작성한 Spring설정 git코드]
https://github.com/iswoos/main-replication
GitHub - iswoos/main-replication: main-replication 적용코드
main-replication 적용코드. Contribute to iswoos/main-replication development by creating an account on GitHub.
github.com
[문제상황 해결]
1. application.yml파일 로드불가 상태
@ConfigurationProperties를 이용하여 yml의 특정 설정값들을 읽으려하였으나,
Spring Boot Configuration Annotation Processor not configured에러가 발생하였다.
그럼으로써 application.yml에 있는 slave-list값들이 연동되지 않았다는 표시가 떠서 작동이 불가하였다.


해당 이슈를 해결하고자, build.gradle의 dependencies에 하기와 같이 설정한 후 다시 build를 진행하였다.
dependencies {
...
annotationProcessor "org.springframework.boot:spring-boot-configuration-processor" // Use ConfigurationProperties
}
build 후에는 아래와 같이 변경되었다.

몇가지 확인을 해본 결과, 캐시가 쌓여서 오작동이 일어나는 경우가 있다는 글을 발견하였다. 그리하여 캐시 제거를 위해 아래와 같이 추가 처리하였다.
● 1. 프로그램에서 상단 메뉴바에 file를 클릭합니다. 그리고 "Invalidate Caches"를 선택합니다.

[참고내용]
https://earth-95.tistory.com/103
[Springboot, IntelliJ] Re-run Spring Boot Configuration Annotation Processor to update generated metadata
이슈 원인 @ConfigurationProperties를 사용하여 yaml의 특정 설정값들을 읽으려했고, 이때 하기와 같이 Spring Boot Configuration Annotation Processor not configured 에러가 발생했습니다. 해당 이슈를 해결하고자 buil
earth-95.tistory.com
2. p6spy로 인한 오류
해당 블로그를 참조하여, 에러를 해결하였다.
기존에 build.gradle에 있는 p6spy를 제거함으로써 문제를 해결하였다.
[참고내용]
Spring Data JPA - Write, Read Only 분리 적용하기 - 2. 무력화 되는 경우
이전 포스팅을 통해 Spring Data JPA를 사용하면서 AbstractRoutingDataSource, LazyConnectionDataSourceProxy를 사용하여 Write, Read Only DB를 분리하여 사용하는 방법의 원리를 알아보았다. 그럼 이 설정을 무력화하
devs0n.tistory.com
3. JPA entityManager설정 오류
아래와 같이, 내가 사용할 패키지 경로를 "com.ono.omg"대신 대체하여 교체함으로써, 올바르게 JPA에서 사용할 부분을 세팅하였다.
// JPA 에서 사용할 entityManager 설정
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactory() {
EntityManagerFactoryBuilder entityManagerFactoryBuilder = createEntityManagerFactoryBuilder(jpaProperties);
return entityManagerFactoryBuilder.dataSource(dataSource()).packages("com.ono.omg").build();
}
# 내가 사용할 패키지 경로를 "com.ono.omg" 를 대체하여 넣어주면 된다.
[테스트 실행결과]
- /test/java/aws/masterslave/service/ProductServiceSimpleTest.SLAVE_읽기()
- Case: READ
- Required: @Transaction(readOnly=True)
- Result: Slave
-

- /test/java/aws/masterslave/service/ProductServiceTest.비관적_락()
- Case: PessimisticLock
- Required: STOCK = 1000, THREAD_COUNT = 900
- Result: STOCK - THREAD_COUNT = 100

- JMeter
- Case: time: 7sec , Request: 200

DB분산을 처음 해봤는데, 확실히 어려운 것 같다.
하지만 이번에도 좋은 경험이였다.
[참고링크]
https://junghwanta.tistory.com/16
2. Database - Replication( + AWS Read Replica)
Replication 데이터베이스의 안정성과 관련된 기능중 Replication에 대해 공부를 하였다. Replication은 여러가지 DB 서버가 있을 때, 각각의 서버가 동일한 데이터를 가지도록 하는 기술을 말한다. (사실
junghwanta.tistory.com
Spring - AWS RDS로 MySQL Replication 적용하기 (feat. 다중 AZ)
모든 코드는 Github에 있기 때문에 함께 보시면 더 이해하기 쉬우실 것 같습니다.(공부한 내용을 정리하는 Github와 이 모든 내용을 담고 있는 블로그가 있습니다. )데이터베이스 이중화 방식 중 하
velog.io
GitHub - backtony/blog-code: 개인 블로그 예제 code
개인 블로그 예제 code. Contribute to backtony/blog-code development by creating an account on GitHub.
github.com
http://kwon37xi.egloos.com/m/5364167
Java 에서 DataBase Replication Master/Slave (write/read) 분기 처리하기
대규모 서비스 개발시에 가장 기본적으로 하는 튜닝은 바로 데이터베이스에서 Write와 Read DB를 Replication(리플리케이션)하고 쓰기 작업은 Master(Write)로 보내고 읽기 작업은 Slave(Read)로 보내어 부하
kwon37xi.egloos.com
https://jojoldu.tistory.com/506
Spring Batch ItemReader에서 Reader DB 사용하기 (feat. AWS Aurora)
일반적으로 서비스가 커지게 되면 DB를 여러대로 늘리게 됩니다. 이때 가장 첫 번째로 고려하는 방법이 Replication 입니다. 즉, 1대의 마스터 DB와 여러대의 Slave DB를 두는 것이죠. 데이터의 변경은
jojoldu.tistory.com
'★ 프로젝트 + 트러블 슈팅 ★' 카테고리의 다른 글
| [Reverse Geocoing] RestTemplate 활용 네이버 API 사용법 (만남의 광장) (0) | 2023.02.15 |
|---|---|
| WAS 최대 쓰레드의 의미 (2) | 2022.12.16 |
| ★ 대규모 트래픽 부하테스트 ★ ALB (Application-Load-Balancing) + Auto-Scaling 진행순서 및 트러블 슈팅 (0) | 2022.12.13 |
| ★단일 서버 성능개선 트러블 슈팅★ (주 트래픽이 무엇인지를 파악하는 습관을 기르자) (0) | 2022.12.13 |
| CI/CD 트러블 슈팅 2 (0) | 2022.12.13 |



댓글