Mysql을 공부하던 중, Mysql의 스토리지 엔진인 InnoDB에서는 인덱스를 관리할 때
B+tree 방식을 사용한다고 한다.
그래서 해당 방식을 차용하게 된 과정을 거슬러올라가며 개념을 정리하고자 한다!
그러기 위해서 우선 이진탐색 트리(BST)부터 시작하고자 한다.
(자료는 점점 채워나갈 예정이다 ㅎㅎㅎ..)
이진탐색 트리 (BST)
모든 노드의 왼쪽 서브 트리는 해당 노드의 값보다 작은 값만 가지며, 오른쪽 서브트리는 큰 값만 가지는 형태

> 특징
1. 자녀 노드는 최대 2개까지만 가능
> 시간 복잡도
편향 트리일 땐 O(logN), 일반적일 땐 O(logN)
BST의 해당 특징 및 시간복잡도로 인해서 선대 개발자님들은 고민을 하게 되었다.
1. 어떻게 하면 자녀 노드를 최대 2개가 아닌, 여러 개를 가질 수 있게 할까?
2. 시간 복잡도를 어떻게 더 효율적으로 만들 수 있을까?
그렇게 생겨난 B tree는 아래와 같다
B tree
이진탐색 트리를 일반화한 트리
> 특징
1. 부모 노드는 자녀 노드를 2개 이상 가질 수 있다
2. 노드가 자녀를 X개 가졌다면, Key는 X-1개를 가진다
3. 노드 내의 Key들은 오름차순으로 저장된다
4. 모든 leaf 노드들은 같은 레벨에 있다.
> 시간 복잡도
모든 경우에 대해 O(logN)
위 특징을 보면 BST에 비해 아래와 같은 몇가지 장점이 생겨나게 되었다
1. 자녀 노드를 2개 이상 가질 수 있음 (제일 중요)
2. 모든 leaf 노드들이 같은 레벨이 있음으로써 편향 트리가 되지 않음 (시간 복잡도가 O(logN)이 된다)
3. 노드의 깊이를 단축시킬 수 있어, 데이터를 찾을 때 탐색 범위를 빠르게 좁힐 수 있음
근데 이것만 보고 왜 DB들이 index로 B tree 방식을 BST보다 더 선호하는지 명확하게 알기 어렵다
그 이유에 대해 알기 위해 우선 컴퓨터의 메모리 구조를 보면 이해가 쉬울 것 같다!
컴퓨터 메모리 구조
아래에 있는 요소들의 설명은 다음과 같다
> CPU
1. 프로그램 코드가 실제로 실행되는 곳
> Main memory (주기억 장치) / RAM
1. 실행 중인 프로그램의 코드들과 코드실행에 필요한, 혹은 그 결과로 나온 데이터들이 상주하는 곳
전원이 꺼지면 데이터가 삭제되는 휘발성 메모리
> Secondary storage (보조기억 장치) / SSD, HDD
1. 프로그램의 데이터가 영구적으로 저장되는 곳
2. 실행 중인 프로그램의 데이터의 일부가 임시 저장되는 곳
3. 데이터 처리 속도가 가장 느림
4. 데이터 저장 용량이 가장 큼
전원이 꺼져도 영구적으로 기억이 가능한 비휘발성 메모리

그럼 DB는 위 메모리 구조 중 어디에 속할까?
Disk기반인 DB는 바로 Secondary storage에 속하며, 특징은 아래와 같다.
> DB
1. DB는 Secondary storage (보조기억 장치)에 저장됨
> 데이터 처리 속도가 가장 느림
> 데이터 저장 용량이 가장 큼
2. DB에서 데이터를 조회할 땐, Secondary storage에 최대한 적게 접근하는 것이 성능 면에서 좋음
3. block 단위로 읽고 쓰기 때문에 연관된 데이터를 모아서 저장하면 더 효율적으로 읽고 쓸 수 있음
위 DB에 특징들에 근거한, DB에서 B tree를 선호하는 이유는 아래와 같다
B tree 계열을 DB 인덱스로 선호하는 이유
쉬운 설명을 위한 가정 몇 가지 (아래 그림참조)
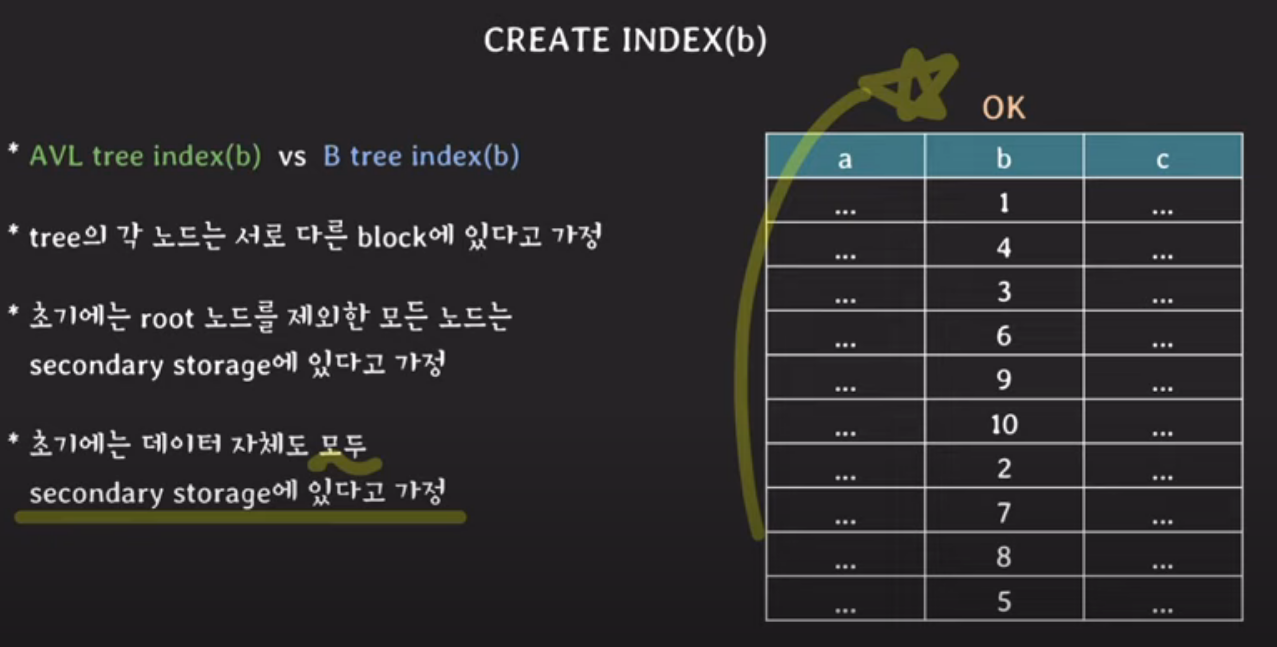
위 가정을 토대로 우측의 데이터를 기반으로
균형이진트리(AVL)과 B tree를 만들면 아래와 같은 그림이 나온다
여기서 만약 b가 5인 데이터를 찾는 조건이 주어지면,
각자 secondary storage에 4번 / 2번 이라는 접근 횟수를 보인다.

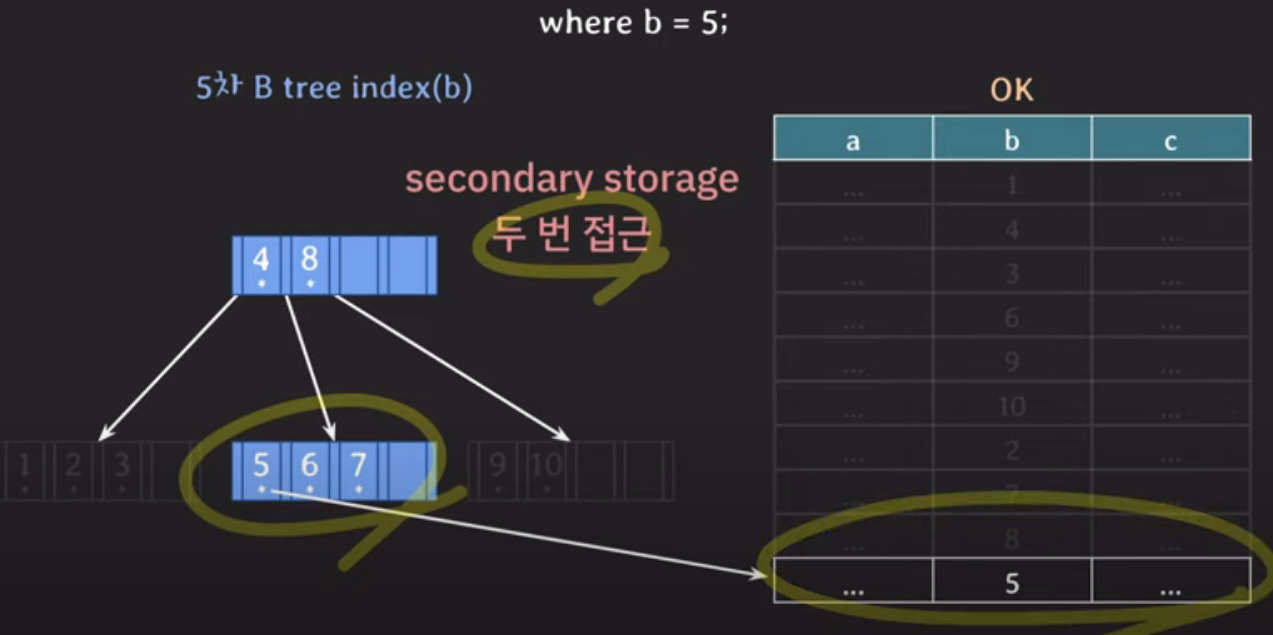
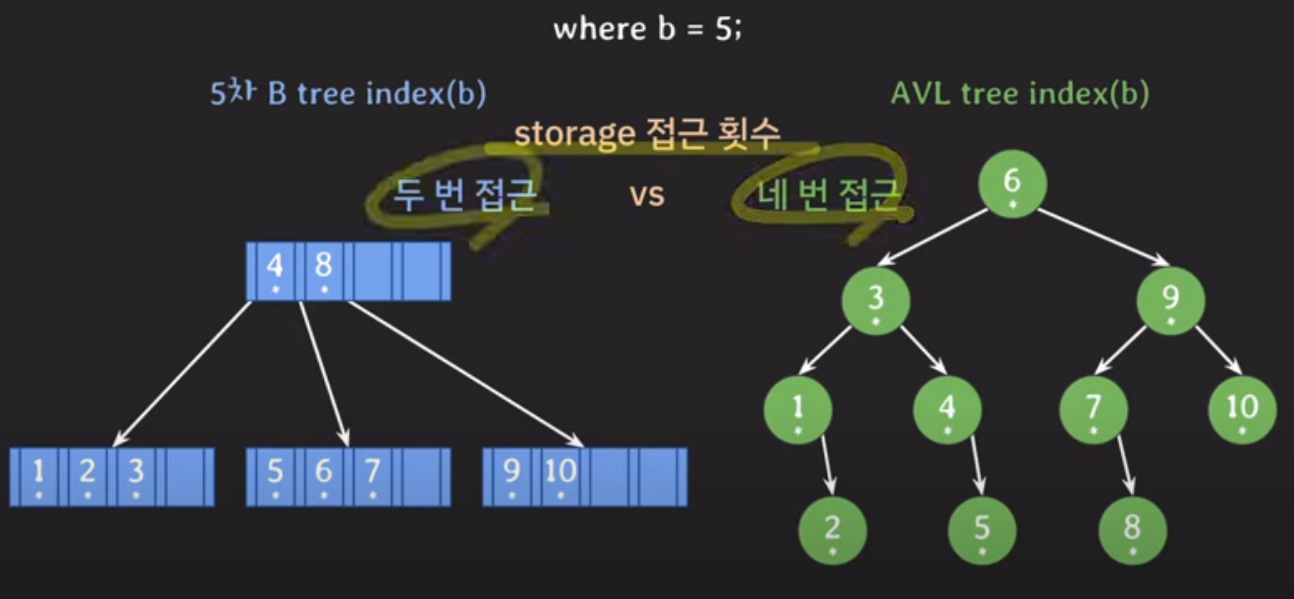
왜 이런 차이가 생기는지 생각해보면 금방 아래와 같은 답을 생각하게 된다!!
아래 2가지의 답은 서로 상호보완적이다
1. B tree는 자녀 노드를 2개 이상 가질 수 있다
데이터를 조회할 때 탐색 범위를 빠르게 좁힘으로써 Secondary storage(보조기억 장치) 접근이 적다
2. B tree의 노드는 여러 개의 데이터를 저장할 수 있다
block 단위의 저장공간 활용도가 높다
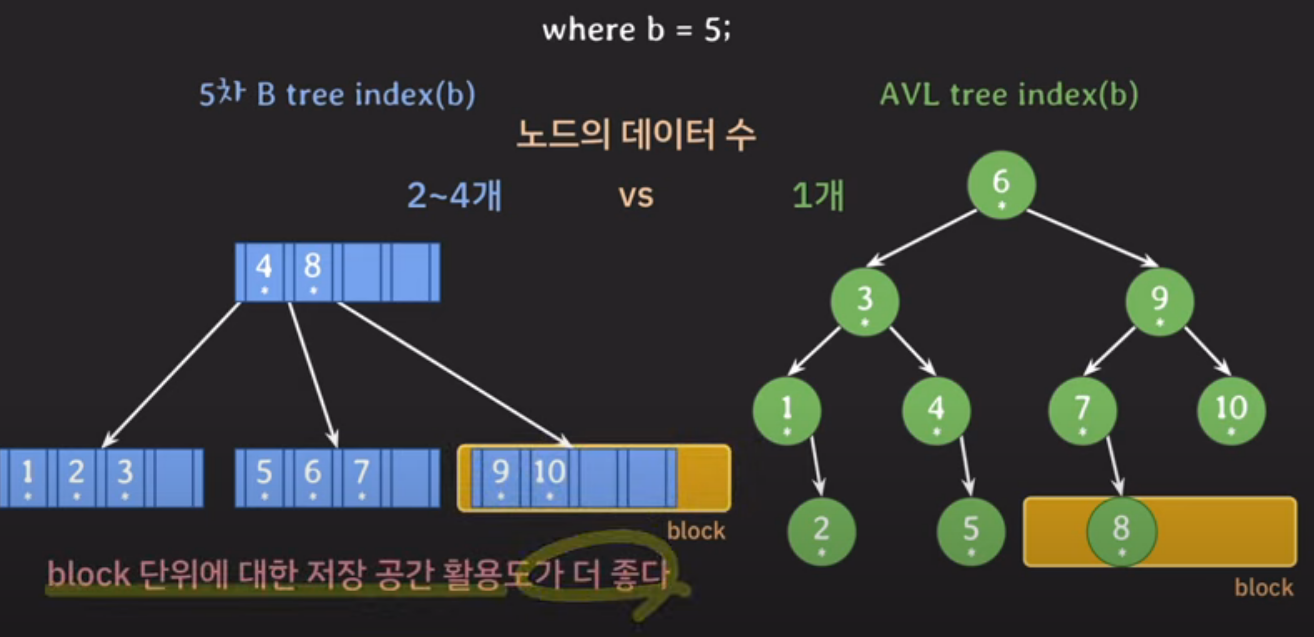
위 2가지 이유를 더 자세히 풀어보면 아래와 같이 설명이 가능하다.
1. 한 노드에 데이터를 여러 개 저장
2. 여러 개의 자녀노드 생성
3. BST / AVL에 비해 노드 깊이가 단축됨
4. 데이터를 조회할 때, 찾으려는 데이터의 탐색 범위를 더 빠르게 좁힐 수 있음
=> Secondary storage에 접근하는 횟수 자체를 줄일 수 있음
이런 이유로 B tree를 더욱 선호하는 것이다
여기까지가 우선 정리한 것들이며, B+tree에 대해 더 알아볼 예정입니다.
현재까지 B+tree는 B tree와 다르게 루트 노드에 key값만 저장한다고 본 것 같은데, 더 자세히 봐야 이해가 갈 것 같습니다
댓글