노션에 따로 정리둔인 것들을 미리 옮겨놓았습니다
MongoDB란?
NoSQL DB이다.
- key-value와 다르게 범용적으로 사용 가능
- 스키마를 고정하지 않는 형태
- 데이터를 구조화해서 json형태(key-value화)로 저장
- join이 불가능하기 때문에 join이 필요없도록 데이터 설계 필요
- 특징
- 메모리맵 형태의 파일엔진 DB → 메모리 크기가 성능을 좌우
- 쌓아놓고 삭제가 없는 경우가 적함(트랜잭션이 필요한 경우는 부적합)
- 도큐먼트 데이터 모델
NoSQL이란?
- Not Only SQL의 준말이며, SQL을 사용하는 관계형 DB가 아닌 DB를 의미함
RDBMS vs NoSQL

MongoDB를 왜 써야하나?
인터넷 서비스가 점점 많은 곳에 보급되고 데이터를 전송하는 device의 수가 증가하게 되면서, 전통적인 RDB로는 취급하기 어려운 방대한 양의 비정형 데이터들을 적재하고 처리하기 위해 새로운 data storage가 필요했음
즉, RDBMS의 한계를 극복하고자 함이 NoSQL의 등장 이유임. 여기서 말하는 RDB의 한계란 아래와 같음
- 비정형 데이터를 처리하기가 힘듦
- 확장성이 떨어
- 상대적으로 속도가 느림
이를 MongoDB는 아래와 같은 특성으로 문제를 해결하기에, 사용이유가 명확해짐
여기저기서 데이터들이 마구 쏟아져 들어오는 상황에서
- 데이터 포맷을 크게 신경 쓰지 않고 일단 때려 담을 수 있음
- DB 서버 용량이 넘칠 것 같으면 쉽게 새로운 서버를 옆에 팍팍 붙여서 확장할 수 있음
- 엄청난 빈도로 읽기/쓰기 연산을 해도 performance에 큰 문제가 없음
MongdoDB 자료구조
MongoDB는 Document Data Model이기 때문에 아래와 같은 특징이 있다.
특징
- 속성의 이름과 값으로 이루어진 쌍의 집합
- 속성은 문자열이나 숫자, 날짜 가능
- 배열 또는 다른 도큐먼트를 지정하는 것도 가능함
- 하나의 Documnet에 필요한 정보를 모두 담아야 함
- one Query로 모두 해결이 되게끔, Collection model 설계를 해야 함
- Join이 불가능하므로, 미리 Embedding 시켜야 함
장점
- Schema-less 구조
- 다양한 형태의 데이터 저장가능
- 데이터 모델의 유연한 변화가능(데이터 모델변경, 필드확장 용이)
- Read/Write 성능 뛰어남
- Scale out구조
- 많은 데이터 저장가능
- 장비 확장이 간단함
- Json구조이기에, 데이터를 직관적으로 이해하기가 가능함
단점
- 데이터 업데이트 중 장애 발생 시, 데이터 손실가능
- 많은 인덱스 사용 시, 충분한 메모리 확보 필요
- 데이터 공간소모가 RDBMS에 비해 많음 (비효율적인 Key 중복입력)
- 복잡한 Join 사용 시 성능 제약이 따름
- Transaction 자원이 RDBMS 대비 미약함
- 데이터가 여러 컬렉션에 중복되어 있기 때문에, 수정(update)를 해야하는 경우 모든 컬렉션에서 수행해야 함
- 데이터 정합성 보장 안됨
📌사용처
🌟쌓아놓고 삭제가 없는 경우가 제일 적합 ex) 로그데이터, 세션
- 정확한 데이터 구조를 할 수 없거나 변경/확장 될 수 있는 경우
- 읽기(read)처리를 자주하지만, 데이터를 자주 변경(update)하지 않는 경우 (즉, 한번의 변경으로 여러 문서를 변경할 일이 없는 경우)
- 데이터베이스를 수평으로 확장해야 하는 경우 (막대한 양의 데이터를 다뤄야 하는 경우)
MongoDB의 핵심, 분산 시스템
아래에서 생각하는 것처럼 웹 서비스가 발전하면서 데이터 무결성을 버리면서까지 더 많은 데이터, 빠른 성능, 수평 확장이 필요한 데이터베이스가 필요해졌다. 그런 요구 사항으로 인해 MongoDB가 탄생했다.

그런 이유로 분산 확장이 가능하다
데이터를 여러 서버에 더 쉽게 분산해주며, 도큐먼트를 자동으로 재분배하고 사용자 요청을 분배하여 라우팅함으로써 클러스터 내 데이터 양과 부하를 조절할 수 있다.
분산 시스템을 위하여 샤딩 아키텍처를 중요시하고 있다.
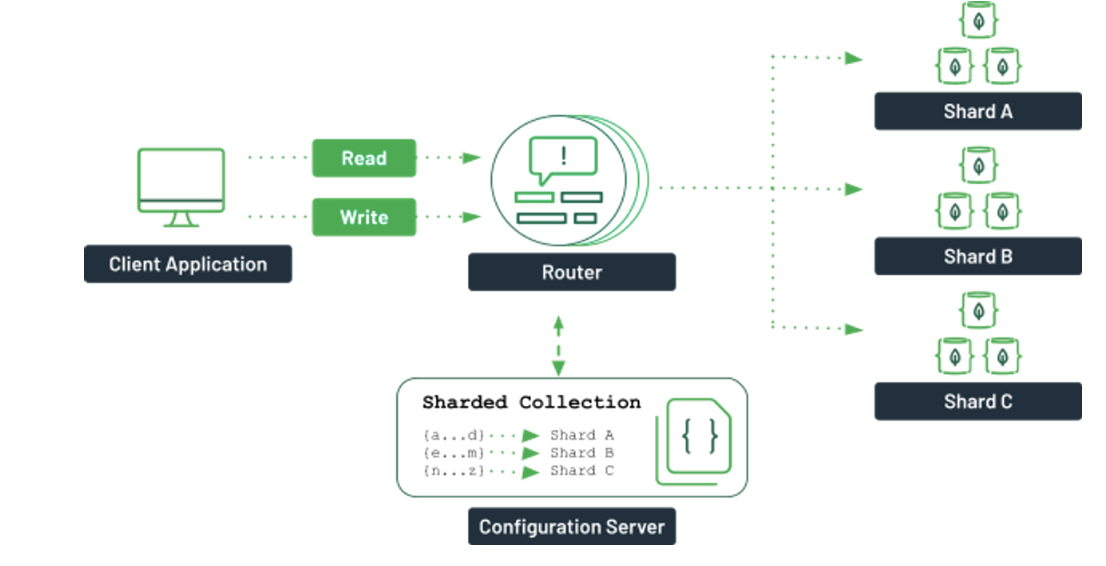
몽고 DB 프로젝트의 주 관심사는 확장성이 높으며 유연하고 빠른, 즉 완전한 기능을 갖춘 데이터 스토리지를 만드는 일이다.
궁금사항
- 몽고 DB는 클러스터 크기, 네트워크 및 애플리케이션에 의해 성능이 결정되는데, 서비스에 맞는 클러스터의 크기를 기준치가 별도로 존재하는지?
- 도큐먼트의 분배로 인하여 발생할 가능성이 있는 이슈가 있는지?
- 데이터 동기화 등등…
- 임베디드 방식과 레퍼런스 방식 중 선택해야 하는 상황이 있을 경우, 결정의 기준은 무엇으로 잡아야 하는지?
Join이 많이 발생하는 구간은 임베디드 방식으로하는 게 효율적이려냐?
도큐먼트의 일부만 리드하는 상황일 경우, 레퍼런스 방식을 진행한다. 로드하는 것이 무엇이냐에 따라서 임베디드랑 레퍼런스로 나눈다.
액세스 패턴에 따라서 모델링을 다양하게 가져가는 게 중요하다.
- Atlas Search 서비스 Full Text Search 지원 자연어 처리 / 정교한 텍스트 바인딩 / 고급 검색기능 지원
- 인터넷에 있는 자료들마다 내용이 상이해서 그러는데, Transaction도 지원하는지? 만약 아니라면, ACID 구조가 불가능한 것인지?>> SQL에서 사용하는 ACID를 똑같이 사용할 수 있다
- 동시성 제어는 어떻게 하는지? RDB와 동일하게 Lock을 활용하는지? MVCC를 보았는데, 이것으로 동시성을 제어하는지?
SQL에서 사용하는 걸 거의 다 MongoDB에서 지원해줌.
OATP?
BQUERY? EQUERY?
워크로드?
ETL절차?
GCP의 용도
오로라 DB는 지금 우리 회사가 무슨 용도로 사용하고 있지?
다이나모DB를 현재 로그수집 용도로 사용하고 있다. 검색용도가 아니고 적재용도로 사용하고 있음. 다이나모DB에서 S3로 보냄. 라이브로 로그를 읽는애들은 loggly를 쓰고 있음
서비스 실습하는 자리를 2~3분정도 모집하여 진행하는 세션을 만들고 계심.
- 조회용도로 도입하기 위해서 어떤 과정을 겪어야하는지 (예시: 어떤 식으로 조회용 데이터를 몽고DB에 이관/저장 시켰는지)
- 로그/통계 수집용도로 어떤 과정을 거쳐 도입시켰는지
- 추후 운영하면서 겪은 이슈사항이 있었는지
몽고DB 주문데이터 로그성으로 관리하는데 (다나와, 에누리 등 전부 적재 -> N천만 단위)
- MongoTemplate 사용해서 List로 한 번에 적재
- 대부분의 통계는 빅데이터 팀에서 하는데, 본인이 처리하는 통계는 로그 찍어서 엘라스틱서치 사용
- 큰 이슈 없다
참조링크
https://www.youtube.com/watch?v=81JnYGT2HVQ&list=PL9mhQYIlKEheyXIEL8RQts4zV_uMwdWFj&index=4
https://inpa.tistory.com/entry/MONGO-📚-몽고디비-특징-비교-구조-NoSQL
Spring boot에 MongoDB 연동하는법
'개인공부' 카테고리의 다른 글
| [Elasticsearch] 데이터 매핑 및 색인화 (0) | 2025.03.16 |
|---|---|
| 헥사고날 + 멀티모듈 학습 (모듈간 의존성 약화) (0) | 2024.02.04 |
| VPN VPC 개념 (1) | 2023.11.29 |
| Oauth2 (0) | 2023.10.16 |
| Redis 개념 및 사용법 (0) | 2023.06.03 |



댓글